JOURNAL 2980
Records of Agricultural and Food Chemistry
Year: 2023 Issue: 2 July-December
p.36 - 44
Viewed 2289 times.
GRAPHICAL ABSTRACT
ABSTRACT
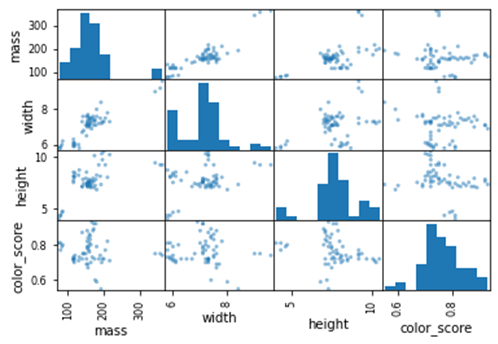
Fruits contain vitamins and dietary fibers, a vital source of the human diet. According to fruit production statistics, millions of metric tons of fruits was produced worldwide, and the advanced agricultural fruit recognition system with a simple camera or sensor will play an excellent role for farmers and general people. For the classification of fruits and vegetables, the features that come to mind first are sizing, color, and smell. The other ones are physical, chemical, and biological properties, and their tastes are important for identification, too. Such features also provide a perfect environment for creating imbalanced and incomplete datasets under the open-set protocol. The traditional methods that include a physical inspection of each fruit are less efficient, resulting in the development of more efficient and effective classification algorithms. Data mining algorithms for classification is operated in some software without being directly coded, KNIME, or can be modeled in code-able software such as PYTHON. It is a widely used high-level, general-purpose, interpreted, dynamic programming language, and pandas, numpy, matplotlib, and scikit-learn packages is frequently used as the basis for programming with PYTHON. This work aims to distinguish between different types of fruits using a simple dataset for the task of training a classifier. In this study prepared using the data, 59 fruit samples with the species name, subspecies name, weight, width, height, and color properties were analyzed using Decision Tree (DTR), K-Nearest Neighbors (KNN), Linear Discriminant Analysis (LDA), Gaussian Navie Bayes (GNB) and Support Vector Machine (SVM) classifiers. Accuracy values for each classifier were defined and compared with each other, and then the classifier with the highest accuracy was examined in detail. In the decision tree of samples classified according to fruit names, it is understood that height is the most effective measure in classifying fruits, and they are in the Bin 1 class (15 pieces). The second effective one is in the Bin 1 class (15 units) with height. The third effective one is in the Bin 1 class with width (12 peaces).
KEYWORDS
- Fruit
- Classification
- Python
- Decision Tree
- Accuracy
